🪽 AgentFly¶
Training scalable LLM agents with RL (multi-turn, asynchronous tools/rewards, multimodal)
Note
Parts of this documentation are AI-generated. We aim to keep it accurate, but if you find a discrepancy with the code, the code is the source of truth — please open an issue or PR.
Resources¶
-
AgentFly: Extensible and Scalable Reinforcement Learning for LLM Agents
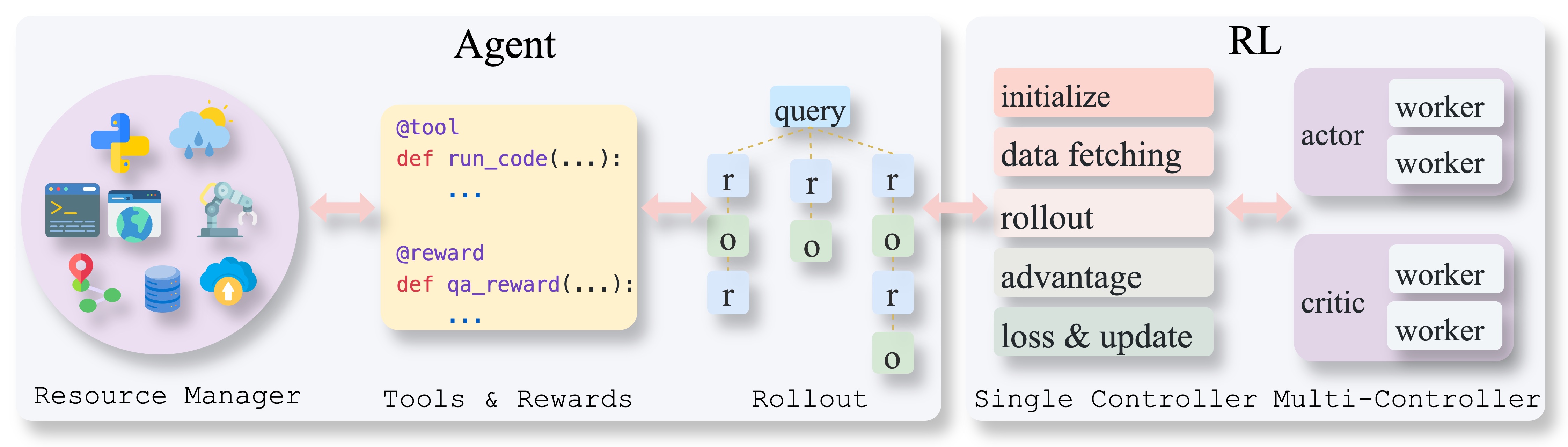
Methods to build LLM agents have evolved from prompt engineering and supervised finetuning to agentic reinforcement learning (agentic RL). AgentFly is an agentic RL framework that tackles bottlenecks in environment interaction, reward calculation, and large-scale training through a four-layer design: an agent layer for defining agents, tools, and rewards; a rollout layer that drives agent loops and collects trajectories; a context layer that injects task metadata and coordinates resources; and a resource layer that manages low-level execution backends such as containers and model engines. With a suite of prebuilt tools and environments (including search, code, and interactive environments), AgentFly enables scalable training of multi-turn, tool-using LLM agents across diverse tasks.
-
GitHub Repository
Code repository in GitHub.
-
WandB
The training curves, parameters, rewards, and trajectories.
-
HuggingFace
Check out the models on Hugging Face. Agent for code interpreter, retrieval, ScienceWorld, WebShop, etc.
-
Tutorials
Check out the tutorials on how to build agents, tools, rewards, and start training.
Welcome to join our community!¶
-
WeChat Group
Scan to join WeChat group.

-
Discord
Join our Discord community.
